

Why Arabic Is One of the Hardest Languages for AI Speech Systems — and Why That Matters for Language Learners
[Part 1 of a Series on Arabic, AI, and Speech Modeling]
For many years, my work focused primarily on Arabic language proficiency, assessment, curriculum development, and the challenges facing learners navigating the relationship between Modern Standard Arabic (MSA) and spoken dialects.
Over time, however, I became increasingly interested in a broader question:
Could some of the same principles that help humans learn language also help us improve how AI systems process language?
While Artificial Intelligence does not learn exactly the way the human brain learns, modern AI systems increasingly borrow functional principles that resemble aspects of human learning and cognition. Contextual exposure, repetition, feedback loops, pattern recognition, scaffolding, adaptive interaction, and authentic input all play important roles in both language education and modern AI model training.
This intersection between human learning and machine learning became particularly interesting to me in the context of Arabic.
Language teachers and linguists have spent generations studying how humans acquire language in real communicative settings. We know that successful language learning involves far more than memorizing grammar and vocabulary. It also requires navigating:
- sociolinguistic context
- audience and setting
- register variation
- implied meaning
- dialect shifts
- pragmatic inference
Ironically, many of these same factors now represent major challenges for modern AI language systems. Arabic provides one of the clearest examples of this problem.
Unlike languages that operate within relatively stable spoken and written forms, Arabic functions along a dynamic continuum between Modern Standard Arabic and regional dialects. Speakers move naturally between formal and informal registers depending on audience, topic, purpose, and context. Human listeners navigate this continuum intuitively.
AI systems often struggle with it.
***
These issues are not entirely new to me. Years ago, in a presentation delivered at the National Conference for Less Commonly Taught Languages at the University of California, Los Angeles (UCLA), I discussed the Arabic sociolinguistic continuum and its implications for language teaching and assessment.

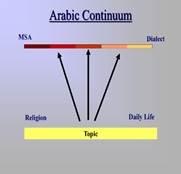
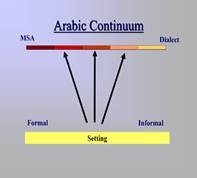
Arabic operates not as a single fixed language system, but as a dynamic continuum between Modern Standard Arabic (MSA) and dialect.
Although modern AI researchers are highly aware of Arabic dialect variation, the sociolinguistic fluidity of Arabic speech continues to present major modeling challenges for ASR, TTS, and multilingual language systems.
==================================================================================================
Today, many of those same linguistic realities are becoming central challenges in:
- speech recognition systems (ASR)
- text-to-speech technologies (TTS)
- dialect modeling
- pronunciation systems
- large language models (LLMs)
As I later began conceptualizing Linguleap — an AI-assisted Arabic learning platform built around authentic contemporary language use — I found myself increasingly reflecting on the overlap between:
how humans learn Arabic and how AI systems attempt to model it.
This article series is therefore not simply about technology. It is also about language itself — and about the growing need for collaboration between AI engineers, linguists, assessment specialists, and language educators as speech technologies continue to evolve.
Artificial Intelligence has made extraordinary progress in speech technology over the past few years. Voice assistants can answer questions instantly, Text-to-Speech (TTS) systems can generate remarkably natural voices, and Automatic Speech Recognition (ASR) systems can transcribe speech in real time with impressive accuracy.
Yet Arabic continues to present some of the most difficult challenges for AI speech systems.
The reasons are not simply technical. They are deeply linguistic, sociolinguistic, and phonological.
Interestingly, many of the same challenges facing AI systems also affect human learners of Arabic. Learners struggle not only with grammar and vocabulary, but with navigating the continuum between Modern Standard Arabic and spoken dialects.
This relationship between Arabic linguistics and AI speech modeling has become increasingly important as companies and researchers attempt to build more accurate multilingual speech systems.
Arabic Is Not a Single Stable Language System
One of the most misunderstood aspects of Arabic is the assumption that it functions as a single uniform language.
In reality, Arabic operates along a linguistic continuum.
At one end is Modern Standard Arabic (MSA), the formal language of education, news media, official communication, literature, and religious discourse.
At the other end are regional dialects such as:
Egyptian Arabic
Levantine Arabic
Gulf Arabic
Moroccan Arabic
Between these extremes lies a broad sociolinguistic spectrum influenced by:
audience
setting
education
topic
formality
An Arabic speaker may move fluidly between registers during a single conversation.
A news presenter may begin in formal MSA, shift toward colloquial speech for emotional emphasis, and then return to formal language again. Political speeches, interviews, television programs, and even classroom discussions often demonstrate this linguistic blending.
For human listeners, this shifting continuum is natural.
For AI systems, it creates a major problem.
Most speech models are designed around the assumption of relatively stable linguistic input. Arabic frequently violates this assumption.
Why Arabic Is Difficult for Text-to-Speech (TTS) Systems
Text-to-Speech systems convert written text into spoken language.
In English, this process is already complex. In Arabic, it becomes dramatically more difficult for several reasons.
1. Arabic Usually Omits Short Vowels
Written Arabic often excludes short vowels (diacritics).
For example:
علم
Depending on context, this word could mean:
science
flag
he knew
A human reader can usually infer the correct pronunciation from context. AI systems often struggle unless they are trained on large, highly contextualized datasets.
This challenge is known as the diacritization problem, and it remains one of the central difficulties in Arabic TTS development.
2. Dialect Pronunciation Varies Dramatically
The pronunciation of Arabic changes significantly across dialects.
For example, the letter:
ق
is pronounced differently depending on the region.
Variety Pronunciation
Modern Standard Arabic /q/
Egyptian Arabic /ʔ/
Gulf Arabic /g/
Thus, the same written word may require entirely different phonological realizations.
A TTS system trained primarily on MSA may sound unnatural or incorrect when generating dialect speech.
3. Arabic Speech Depends Heavily on Prosody
Natural Arabic speech relies on:
stress patterns
rhythm
intonation
emphasis
Even when pronunciation is technically correct, AI-generated Arabic speech often sounds “flat” because it fails to capture these prosodic patterns naturally.
This becomes especially noticeable in emotionally expressive dialects such as Egyptian Arabic.
The Challenge of Automatic Speech Recognition (ASR)
If TTS is the challenge of turning text into speech, ASR faces the reverse problem:
Turning real-world speech back into text.
This is equally difficult in Arabic. People rarely speak the way formal Arabic is written.
An Egyptian speaker may begin a sentence in MSA and suddenly switch to colloquial Egyptian vocabulary, regional pronunciation, or even English expressions.
This phenomenon, known as code-switching, creates major challenges for ASR systems.
In addition, Arabic dialects often lack standardized spelling.
For example, the Egyptian word meaning “I want” may appear online as:
عايز
عاوز
3ayez
From an AI perspective, these may appear as different words even though human speakers understand them immediately.
Why Human Learners Face Similar Challenges
Interestingly, many of the same issues confronting AI systems also affect Arabic learners.
Students often discover that learning formal Arabic alone does not fully prepare them for real-world communication.
A learner may understand a formal news article but struggle to follow an everyday Egyptian conversation.
This is not a failure of the learner.
It reflects the linguistic reality of Arabic itself.
Language learners must gradually develop the ability to move across the Arabic continuum:
from formal MSA toward authentic spoken interaction across different registers and dialects
In many ways, learners face the same challenge as AI systems: They must learn how Arabic actually behaves in real life.
Egyptian Arabic as a Case Study
Among Arabic dialects, Egyptian Arabic occupies a unique position. Because of Egypt’s historical influence in cinema, television, journalism, and music, Egyptian Arabic became widely understood across much of the Arab world.
However, Egyptian Arabic also demonstrates many of the exact phonological and sociolinguistic characteristics that complicate AI speech modeling:
- consonant shifts
- vowel reduction
- rapid informal speech
- code-switching
- register variation
These features make Egyptian Arabic both highly influential and technically challenging for speech technologies.
From AI Challenges to Language Learning: The Idea Behind Linguleap
The linguistic realities that complicate Arabic AI systems also influenced the design philosophy behind Linguleap
Linguleap was designed partly in response to the fact that Arabic cannot realistically be treated as a single static language system.
Rather than relying exclusively on isolated textbook sentences, the platform emphasizes:
- authentic contemporary materials
- real-world language exposure
- contextualized learning
- dynamic assessment
- interaction with current media and speech patterns
The goal is not simply memorization but helping learners gradually navigate the relationship between Modern Standard Arabic and authentic communication as it appears in everyday life.
In this sense, some of the same linguistic challenges facing AI speech systems also shape the future of AI-assisted Arabic language learning.
Looking Ahead
Arabic speech technology has made major progress in recent years through:
- larger datasets
- multilingual models
- dialect-aware training approaches
- advances in neural speech synthesis
Yet significant challenges remain.
Future progress will likely depend on systems that treat Arabic not as a single monolithic language, but as a dynamic sociolinguistic continuum.
Ironically, the same insight may also hold true for successful language learning.
Both humans and machines must ultimately learn to navigate not only Arabic grammar, but Arabic linguistic reality itself.
About the Author
Hussny Ibrahim is a linguist, assessment specialist, and founder of Language Leaders LLC and Linguleap, an AI-assisted Arabic learning platform focused on authentic language use, dialect awareness, and proficiency-oriented learning. His work has focused on Arabic proficiency assessment, sociolinguistics, dialect pedagogy, and language evaluation frameworks.
https://play.google.com/store/apps/details?id=com.linguleap.app&hl=en-US&pli=1